Generating metamers of human scene understanding
Ritik Raina1,
Abe Leite1,
Alexandros Graikos1,
Seoyoung Ahn2,
Dimitris Samaras1, and
Gregory J. Zelinsky1
1Stony Brook University 2UC Berkeley
Your eyes sharply sample only a tiny sliver of the world at any moment, yet your brain constructs a rich, complete scene. But what does that internal representation actually contain — and can we make it visible? We introduce MetamerGen, a model that probes the brain's hidden encoding of scenes by generating images that, despite looking physically different, are perceptually indistinguishable from the original. By fusing where you looked with what your periphery sensed, it reconstructs not the scene itself, but what your mind held of it — a new lens into the structure of human scene understanding.
What is the metamer in MetamerGen?
Metamerism is a term originating in color vision that refers to stimuli that are physically different yet perceptually indistinguishable. Two lights with different spectral compositions, for example, can appear identical to human observers because they produce the same response in the eye's photoreceptors. This concept has since been extended to texture perception and visual crowding, offering a powerful lens for inferring the underlying representations that shape what we see.
In the context of scene understanding, two scenes are metameric if humans form equivalent internal representations of them. When a person views scene A, forming some mental encoding, and later views a physically different scene B that produces the same encoding, they believe the two scenes to be identical. Scene metamers therefore reveal what information the brain has encoded and retained from an originally viewed scene — and what it has discarded. By exploring the factors that cause a generated scene to become a metamer, we can investigate the structure of human scene understanding.
An observer views Scene A (with white rings indicating fixation locations) and Scene B. Despite being physically different images, the two scenes produce equivalent internal representations — the observer perceives them as identical. These scene metamers reveal what information the visual system encodes and retains versus what it discards.
MetamerGen: perceptually-informed conditioning
Representing foveal and peripheral visual features
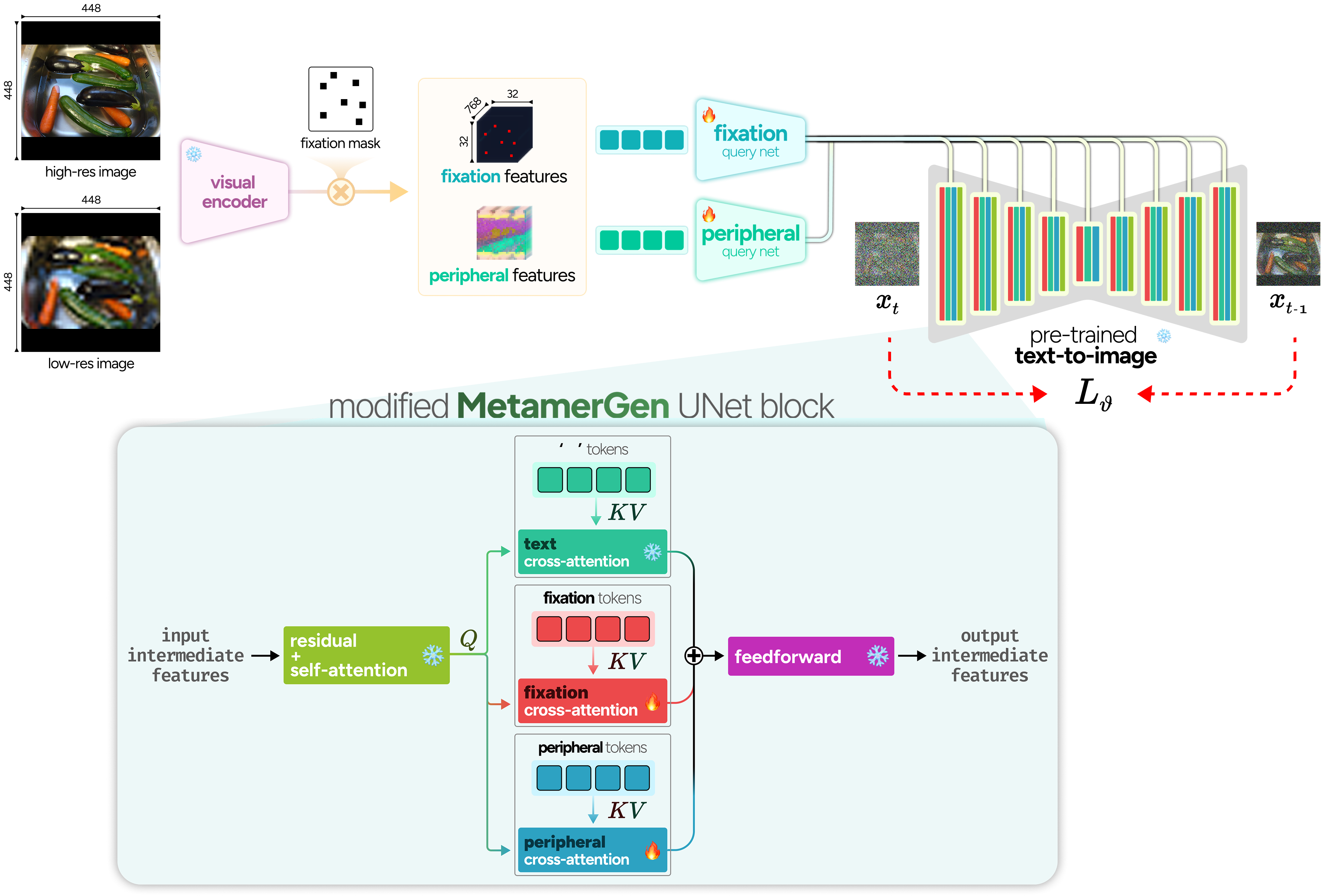
Given an image $I$ and a set of fixation locations (e.g., those fixated by a human during free-viewing), we extract foveal information at each fixation location and peripheral information capturing the overall context. We employ a DINOv2-Base model (with registers) as the feature extractor. DINOv2 processes $448 \times 448$ images with a patch size of $14 \times 14$, yielding $1024$ tokens ($32 \times 32$ grid), each embedded in $768$ dimensions. The patch token at a specific location encodes detailed visual and semantic information analogous to the high-resolution information sampled by the fovea during a fixation. To model the information gathered during a series of fixations, we apply a binary mask $M_{\text{fixation}}$ to the patch tokens, zeroing out all non-fixated image patches.
To obtain peripheral visual features, we downsample the image and then upsample it back to $448 \times 448$. This blurred image, $I_{\text{downsample}}$, is also processed with DINOv2, but now retaining all output patch tokens without masking. These peripheral tokens encode uncertain visual representations across the entire scene, capturing the noisy information available in peripheral vision that requires validation through targeted foveal fixations.
Foveal and peripheral conditioning adapters
We develop foveal and peripheral conditioning adapters to integrate visual information as additional conditioning signals in Stable Diffusion. Similar to IP-adapters, which integrate CLIP image embeddings into Stable Diffusion, we learn how to incorporate DINOv2 patch embeddings into the cross-attention mechanism of the text-to-image Stable Diffusion model. Both foveal and peripheral DINOv2 embeddings are first processed through separate Perceiver-based resampler networks $R(\cdot)$ that compress the $1024$ DINOv2 embeddings into $32$ conditioning tokens compatible with the pre-trained UNet's cross-attention:
$$
e_{\text{foveal}} = R_{\text{foveal}}(\text{DINOv2}(I_{\text{original}}) \odot M_{\text{fixation}}),\quad e_{\text{peripheral}} = R_{\text{peripheral}}(\text{DINOv2}(I_{\text{downsample}}))
$$
The conditions are then integrated through separate cross-attention mechanisms, where for each conditioning source (text, foveal, peripheral) we project separately into keys and values, which we combine additively into the denoising through cross-attention with scaling factors $\lambda_{\text{foveal}}$ and $\lambda_{\text{peripheral}}$:
$$
\begin{aligned}
\text{Attention}(Q, K, V) =\ &\text{softmax}\left(\frac{QK_{\text{text}}^T}{\sqrt{d_k}}\right)V_{\text{text}} \\
&+ \lambda_{\text{foveal}}\cdot\text{softmax}\left(\frac{QK_{\text{foveal}}^T}{\sqrt{d_k}}\right)V_{\text{foveal}} \\
&+ \lambda_{\text{peripheral}}\cdot\text{softmax}\left(\frac{QK_{\text{peripheral}}^T}{\sqrt{d_k}}\right)V_{\text{peripheral}}
\end{aligned}
$$
MetamerGen model architecture. High-resolution and blurred, low-resolution images are processed through DINOv2-Base to extract patch tokens. Foveal features are obtained by applying binary masks to high-resolution patch tokens, retaining only fixated regions. Both foveal and peripheral patch tokens are processed through separate Perceiver-based query networks that compress features into conditioning tokens compatible with Stable Diffusion's cross-attention mechanism. The resulting dual conditioning streams are integrated into the pretrained UNet.
Interactive metamer generations
The interactive metamer explorers below let you adjust the conditioning parameters that determine how metamers are generated. By modifying these settings, you can control the balance between foveal and peripheral information, the degree of peripheral blur, and the number of fixated regions used as input.
Experiment with these parameters to observe how each one affects whether the resulting image qualifies as a metamer of the original. Feel free to explore and experiment with different values.
Behaviorally-conditioned scene metamers
We developed a real-time same-different behavioral paradigm to evaluate whether MetamerGen generates perceptually convincing scene metamers. This paradigm directly tests whether images reconstructed from sparse fixational sampling can achieve perceptual equivalence with the original, thereby revealing the sufficiency of fixated information for scene representation.
Real-time paradigm for determining scene metamers. Each trial begins with drift correction and central fixation, followed by free viewing of an original scene for a predetermined number of fixations. After image offset, participants maintain central fixation for 5 seconds while fixation coordinates are transmitted via API to MetamerGen for real-time image generation. The generated image (or original, depending on the condition) is then presented to the viewer for 200ms, followed by an enforced same-different behavioral judgment via a gamepad within a 10-second response window.
45 participants each completed 300 trials. At the start of every trial, they freely viewed a natural scene until reaching a predetermined fixation count — 1, 2, 3, 5, or 10 — chosen entirely on their own, with eye gaze tracked throughout. Once the image disappeared, they held fixation on a blank screen for 5 seconds while MetamerGen generated a new version of the scene in real time, conditioned on exactly where and when they had looked. They were then shown a second image for just 200 milliseconds — too fast for an eye movement, but sufficient for a perceptual judgment — and asked: same or different?
The second image was either the original scene, or a generation conditioned on one of two fixation strategies: your own fixations or random fixation points within the image. This last condition, evaluated by a separate group of 12 participants, serves as a baseline: how well does MetamerGen fool you when it has no information about where anyone actually looked?
Probing the features of scene metamers
Neurally-grounded hierarchical feature similarity
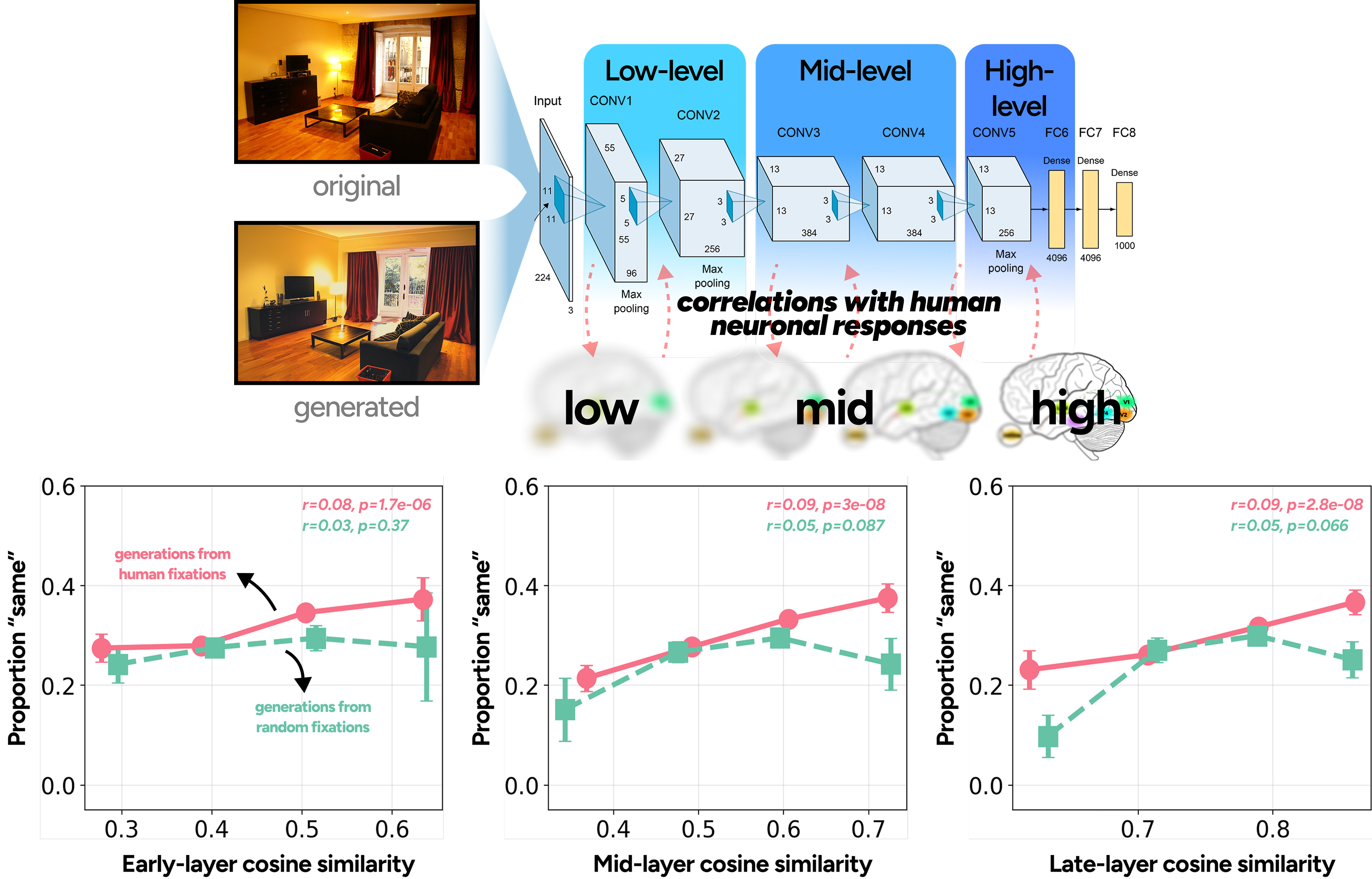
To understand where in the brain metamerism arises, we used a neurally-grounded AlexNet whose internal representations align with visual areas spanning V1 through inferotemporal cortex. By computing feature similarity at early, mid, and late layers, we asked: at what stage does a scene "become" a metamer? The answer: all of them. Higher feature similarity predicted more "same" judgments across every layer — metamerism requires broad alignment, not a single processing stage. But the more telling result is the divergence between fixation-guided and random generations. Despite near-identical metamer rates (29.4% vs. 27.7%), they split at mid and late layers: fixation-guided metamers followed a clean linear trend, while random generations became less convincing as feature similarity increased. Realistic detail in regions you never fixated can, paradoxically, work against you.
Neurally-grounded feature similarity across the visual hierarchy. Original and generated images are passed through a blur-robust AlexNet, with early, mid, and late layers serving as proxies for low- to high-level visual processing. Cosine similarity between feature maps is binned against the proportion of "same" judgments. Generations from a viewer's own fixations (salmon) and from random fixation points (teal) are shown separately across all three processing levels.
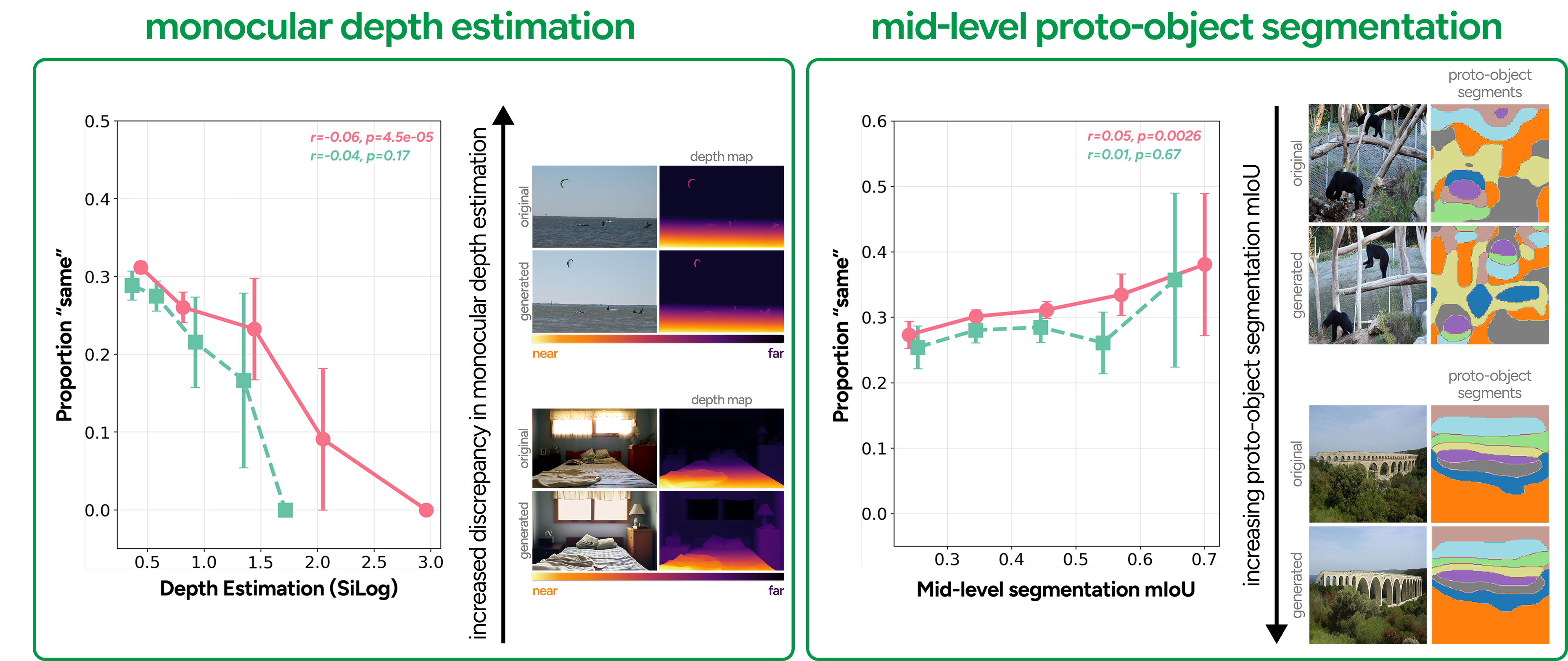
Mid-level visual feature similarities
We next asked whether metamerism is sensitive to mid-level scene structure — the kind of layout information your visual system extracts before it fully parses objects. We focused on two features: relative depth and proto-object segmentation. For depth, we compared depth maps extracted from original and generated images using Depth Anything — as depth discrepancy increased, metamer rates dropped systematically. Scene layout, it turns out, matters. For proto-objects, we used the mid-layer representations of the same neurally-grounded AlexNet from before: these capture the pre-semantic building blocks of visual scenes — local features grouped into simple shapes, before the brain commits to full object recognition. Greater overlap in proto-object segmentation predicted more "same" judgments. Of the two, depth showed the cleaner effect, but both point to the same conclusion: getting the mid-level structure right is non-negotiable for a convincing metamer.
Mid- and high-level visual features predicting metamer judgments. For fixation-guided generations (salmon), increasing depth map discrepancy systematically reduced "same" judgments, while greater proto-object segmentation overlap (mIoU) increased them — though with a weaker effect. On the high-level side, larger DreamSim distances consistently reduced metamer rates, and CLIP similarity showed a similar trend, except for randomly-guided generations (teal).
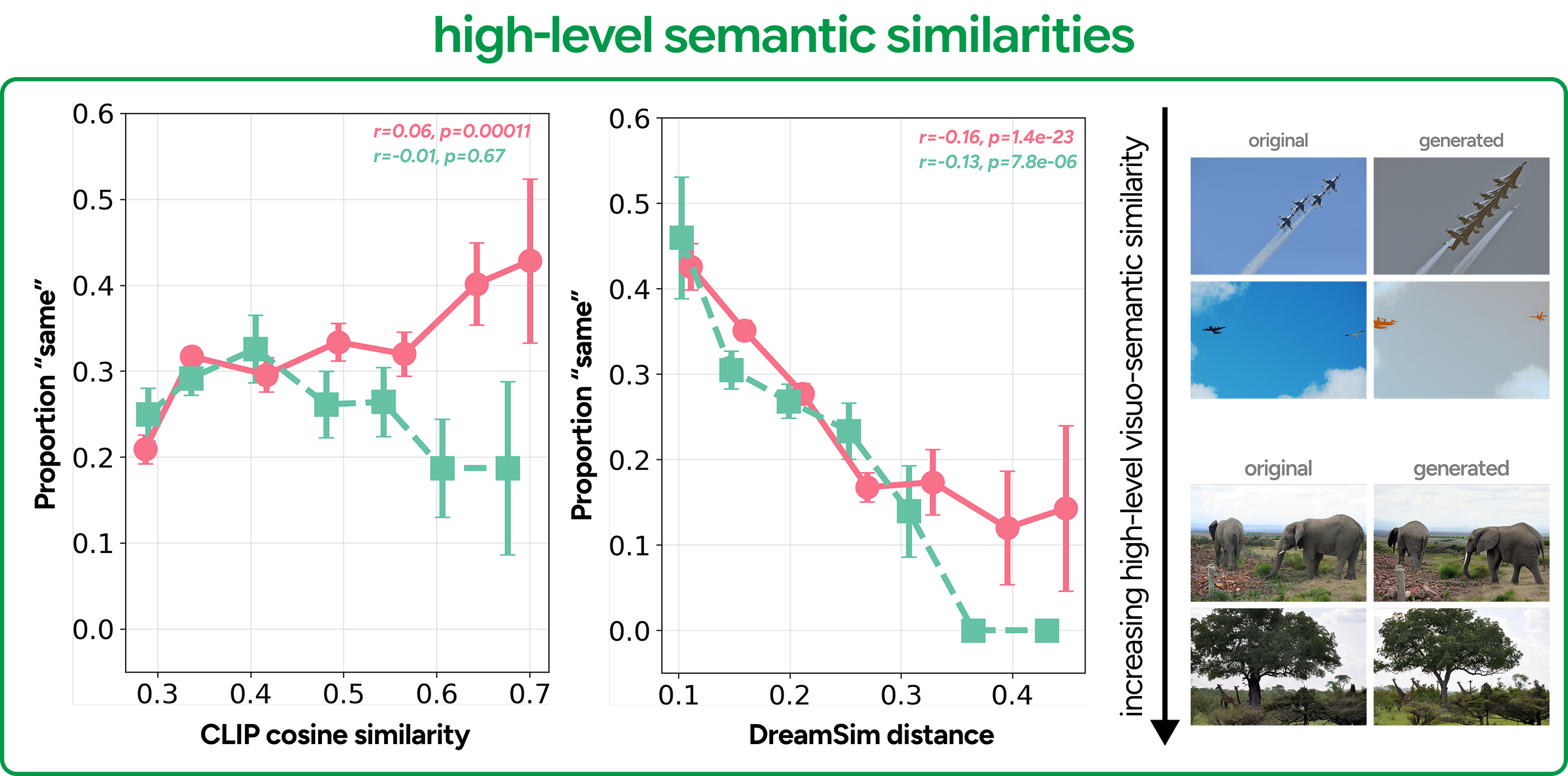
High-level semantic feature similarities
Finally, we asked whether metamerism tracks high-level semantic alignment — how similar the generated scene is in meaning, not just structure. We used two models: CLIP and DreamSim. DreamSim told the clearest story: smaller distances between original and generated images consistently predicted more "same" judgments. CLIP showed the same trend, but with a catch: the relationship held only for fixation-guided generations. For random fixations, higher CLIP similarity did not predict more metamer judgments. We think this reflects the fact that random fixations often land on contextually irrelevant regions, introducing semantic detail that conflicts with what the viewer actually encoded — making the generation feel off even when it looks superficially similar. Together, these results suggest that your own fixations don't just guide where you look — they shape the semantic representation you form, and generations conditioned on them are better aligned with that internal representation.
High-level semantic feature similarities predicting metamer judgments. DreamSim distance and CLIP similarity are plotted against metamer rates for fixation-guided (salmon) and random (teal) generations. Greater semantic alignment predicts more "same" judgments for fixation-guided generations across both metrics. For random generations, this relationship breaks down — particularly in CLIP — suggesting that semantic alignment alone is insufficient when fixations don't reflect the viewer's actual scene representation.
Individual contributions of foveal and peripheral features to metameric judgements
To understand what each conditioning stream contributes, we ran an ablation with 10 additional participants using four second-image conditions: the original scene, a full model generation (foveal + peripheral), a peripheral-only generation, and a foveal-only generation. The results were clear. The full model achieved the highest metamer rate at 54.5%, followed by peripheral-only at 45.8%, and foveal-only at just 8.4%. Foveal-only generations accurately captured fixated details but diverged substantially in the periphery — enough to be reliably detected as different. Peripheral-only generations, by contrast, preserved global scene structure and layout, making them far more perceptually convincing on their own. That said, foveal conditioning is not redundant: when combined with peripheral features, it contributes semantic and visual detail that meaningfully closes the gap — producing generations more aligned with human scene understanding than either stream alone.
Metamer rates across foveal and peripheral conditioning conditions. The full model (foveal + peripheral) achieved the highest fooling rate, followed by peripheral-only, with foveal-only lagging substantially behind. Qualitative examples show that foveal-only generations capture fixated detail but diverge in global structure — making them easy to distinguish — while peripheral-only generations preserve scene layout at the cost of fine-grained detail.
BibTeX
If you find this work useful, please cite using the following BibTeX entry:
@inproceedings{
raina2026generating,
title={Generating metamers of human scene understanding},
author={Ritik Raina and Abe Leite and Alexandros Graikos and Seoyoung Ahn and Dimitris Samaras and Greg Zelinsky},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=cSDXx8V6K9}
}

























An observer views Scene A (with white rings indicating fixation locations) and Scene B. Despite being physically different images, the two scenes produce equivalent internal representations — the observer perceives them as identical. These scene metamers reveal what information the visual system encodes and retains versus what it discards.
Rather than matching low-level peripheral statistics, we capture a post-gist level of representation — combining gist-level scene encoding from blurred peripheral vision with high-resolution foveal representations at fixation locations. The sequence of fixations dictates what the observer understands to be in the scene.